
Creating a secure system or application is not an easy thing. Especially if the system can accept user input from untrusted sources like the internet. In this case, user intent is something that should be considered because in truth, not everyone has good intentions.
This user input is often exploited as a medium for sending malicious code into the system to run the process desired by the attacker. One way that has been commonly used is the buffer overflow attack.
What is buffer overflow vulnerability?
Buffer overflow vulnerability is a security hole that allows an attacker to insert malicious code into a computer system by utilizing the buffer space in memory which is commonly used as a temporary storage medium.
Because basically this attack is carried out by manipulating the memory on the computer, a buffer overflow attack requires deeper knowledge regarding memory layout and knowledge of how a program works on an operating system. For this reason, we will discuss it first before entering the next discussion regarding how buffer overflow works.
The anatomy of memory
The following figure illustrates the memory layout in a memory block.
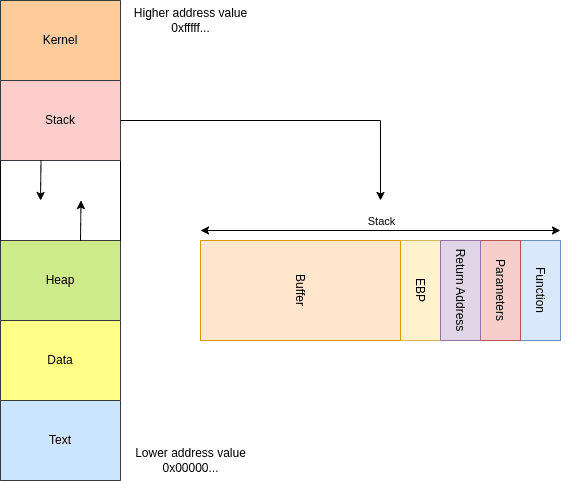
Memory block is a part of RAM (Random Access Memory) that is allocated to store instructions and data that needs to be accessed by a program or operating system. The size of these memory blocks varies, and its management is done by using a technique called virtual memory addressing.
In short, with virtual memory address translation, the operating system will compensate in case of memory shortage by transferring data from RAM to disk storage.
Back to the image above, in a memory block, there are several parts. At the bottom, there is a low memory address of 000… (equivalent to 0x000…) and at the top there is a high memory address of 111… (equivalent to 0xfff…) up to 32 or 64 bits.
The memory block consists of several segments.
- Kernels
The kernel is the core of a computer that is capable of converting user queries into machine language.
- Stack
Segment that stores temporary data such as function parameters, local variables, and return addresses. The stack follows the LIFO (Last In First Out) rule, where recently added data will be removed first. As needed, the operating system or runtime environment allocates and deallocates memory blocks on the stack. A function’s call and return are typically handled automatically as part of the call and return process.
- Heap
The heap is a segment that dynamically allocates data from a running program, such as a buffer. Data allocation can be done by the operating system or the program itself. In contrast to data memory, data stored in the heap is dynamic data, while data stored in data memory is static (stored after the program has finished compiling).
- Data
When a program is executed, the data that has been copied from the disk storage will be placed in this segment. The stored data can vary, either in the form of variables, arrays, or other data that the program will need when it runs. Because this memory data is going to be used by applications, generally this data is read-write.
- Text
When a program is executed, the instructions that have been copied from disk storage will be placed here. The copied instructions are read-only, thereby guaranteeing file integrity and preventing malicious code execution.
Based on the explanation described above, it can be concluded that data allocation on the stack and heap is done dynamically while the program is running. This could be caused by programs that require user input or data from outside the program itself to be able to execute certain commands.
The anatomy of stack
If we examine further, the stack itself has several terms that need to be understood.
- Stack pointers
As the name implies, the stack pointer is used to track the stack. When data is added to the stack (push), it will point to the top of the stack. When the data is removed (pop), the pointer will point to the new data that is located at the top of the stack. This causes the LIFO behavior described earlier.
While doing its job, the stack pointer uses registers that have different functions such as ESP (Extended Stack Pointer) to store the address of the top of the stack, EIP (Extended Instruction Pointer) to store the address of the next instruction to be executed, and EBP (Extended Base Pointer) to store the base address of the current stack frame.
- Stack frames
Stack frame is a memory block where data is stored as follows.
- Function parameters: values that will be used in a function to be able to do its job.
- Return Address: the location where execution takes place after the function returns.
- Saved EBP: storing EBP value.
How does a program work?
Broadly speaking, a program stored in disk storage will be loaded into memory. To do this, program instructions and data from storage (such as a hard drive or SSD) will first be copied to main memory (RAM). Then the program will be compiled or interpreted. Then, the program will be executed by executing the previously copied instructions in the sequence. Finally, the program will be terminated when the instruction ends or a command capable of terminating is called and control is returned to the operating system.
However, some instructions and data of a program may also still be stored in storage media such as hard drives and will be loaded to main memory only if needed to conserve RAM resources.
How does the buffer overflow attack work?
In the memory, there are regions that are used to temporarily store data called buffers. According to its intended use, buffers can come from either heap or stack as both segments are dynamically allocating the running program. This is the reason why buffer overflow attacks are targeted at these two segments and is the basis for classifying the type of buffer overflow attack. Thus, buffers are categorized into two main types based on where they occur, namely stack-based buffer overflow and heap-based buffer overflow.
Buffer overflow occurs when the data that should be placed in the buffer exceeds the size of the buffer so that data will take up other space as shown below.
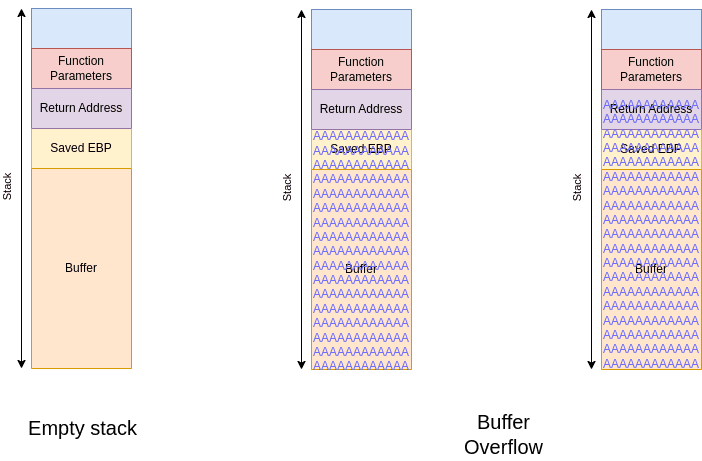
Example of buffer overflow
To get a better overview, let’s take a look at the code below.
Filename: vuln.c
#include <stdio. h>
#include <string. h>
int main(int argc, char **argv) {
charbuffer[50];
strcpy(buffer, argv[1]);
returns 0;
}
The code above is used to demonstrate the use of a buffer on the memory stack. In simple terms, if we enter characters beyond the specified buffer, the data will pass through the buffer area and overwrite it to the segment where it shouldn’t.
I use Linux Mint to run the program above. If you want to try it, you need to
compile the code by yourself, for example, using this command gcc vuln.c -o vuln then run it with the command ./vuln <argument>.
You can try passing a string such as hello as an argument. In this case, the
terminal will not issue any output as the code is executed successfully. The
reason is the hello argument we have entered only contains 5 characters
which is still allowed.
Since we limit the buffer to 50 characters, we can use python code to output up to 50 characters.
python3 -c 'print("\x41" * 70)'
If used directly through the terminal, this code will generate the number of
characters A as long as we want it. The code can also be used as an argument
for the command we have created beforehand. Thus, the command will be as
follows.
./vuln ${python3 -c 'print("\x41" * 70)'}
By running this command, we will get the following result.
*** stack smashing detected ***: terminated
Aborted (core dumped)
This indicates that the data entered has passed through the buffer. In this case, if we try to change the number of characters to a number that is close to the buffer, for example 51, there is a possibility that the above code will still run normally, because this is related to the memory allocation management of your system.
As previously mentioned, the stack will process data dynamically as the program runs. Thus, when an attacker places malicious code in the return address position, it is hoped that the code that has been inserted will be considered as part of the running program and execute it. This may occur in a push and pop mechanism at the beginning and end of a function being executed.
Summary
In summary, a buffer overflow attack is a kind of extremely dangerous cyber attack that can result in consequences for both individuals and organizations. The attack may result in the attacker’s code being written to other areas of memory where it is not supposed to.
In case of an attack, it is common for the attacker to take control of the victim’s computer or do any harmful actions like stealing the sensitive data. Besides, being categorized as a low-level attack, it is really hard to detect and prevent.
Therefore, some efforts to reduce the risk of this from happening have been introduced like randomizing memory layout (ASLR - Address Space Layout Randomization), or from the internal organization context, it is important to enforce best coding practice, the use of safe functions (e.g use strncpy instead of strcpy), and code auditing.