
In today’s world, data holds immense importance and is undeniably valuable. This is particularly true for user data, which is frequently stored in databases. Consequently, adversaries often target these databases to extract valuable information. Among the oldest and most detrimental web application vulnerabilities is SQL Injection. However, in this article, we will not jump into the SQL injection right away. Instead, we will talk a lot about the concepts of SQL and how it works.
Introduction to DBMS
Before going further, we need to define first what the database is. Database is the way to store the collection of data in an organized manner. The data is managed and controlled within an application known as Database Management System (DBMS). In fact, there are a lot of Database types, including: Relational Database, Document Database, Object Oriented Database, etc. Above all, relational databases are the most popular one as it is easier to learn. Another reason is, the way it stores the data is very familiar to us, because the data is stored in the form of tabular (table).
The management of the database also follows the standard command rule called SQL (Structured Query Language). The standardization makes it very easy to switch over another DBMS, so called MySQL, PostgreSQL, Oracle, etc.
General Concepts of Relational Database
In DBMS, you could have multiple databases at once and each database may contain several tables. To make it more clear to you, suppose you are a web developer and you are tasked to build an online shop called “SuperMart”. Therefore, you need to break down what kind of data or info you need to include.
You decide to build a database called “shop”. In this database, you want to add some tables, such as “products”, “users”, and “orders”.
Products Table : This table contains details about the products available for purchase. It includes columns such as product ID, name, description, price, stock quantity, and possibly any relevant attributes.
Users Table : The users table stores information about the individuals who have signed up for the online shop. It contains columns like user ID, name, email, address, phone, and any other required fields.
Orders Table : The orders table maintains records of the orders received by SuperMart. It includes columns like order ID, user ID (linked to the users table), product ID (linked to the products table), quantity, total price, order status, and other relevant information.
As an online shop, perhaps you may also include separate databases for other functional areas, such as “staff” and “account” The staff database contains some information about the company’s staff. Therefore, you need the list for other functional areas:
Staff Database : This database stores information about the company’s staff. It consists of tables like “employee” and “departments”, which contain details such as employee ID, name, position, department ID (linked to departments table), email, and other relevant data.
Accounts Database : The accounts database focuses on financial transactions and accounting. It includes tables such as “invoices” and “payments”, which store details about invoices, payment records, due date, billing information, and other financial data.
With schema, your database may look like this.
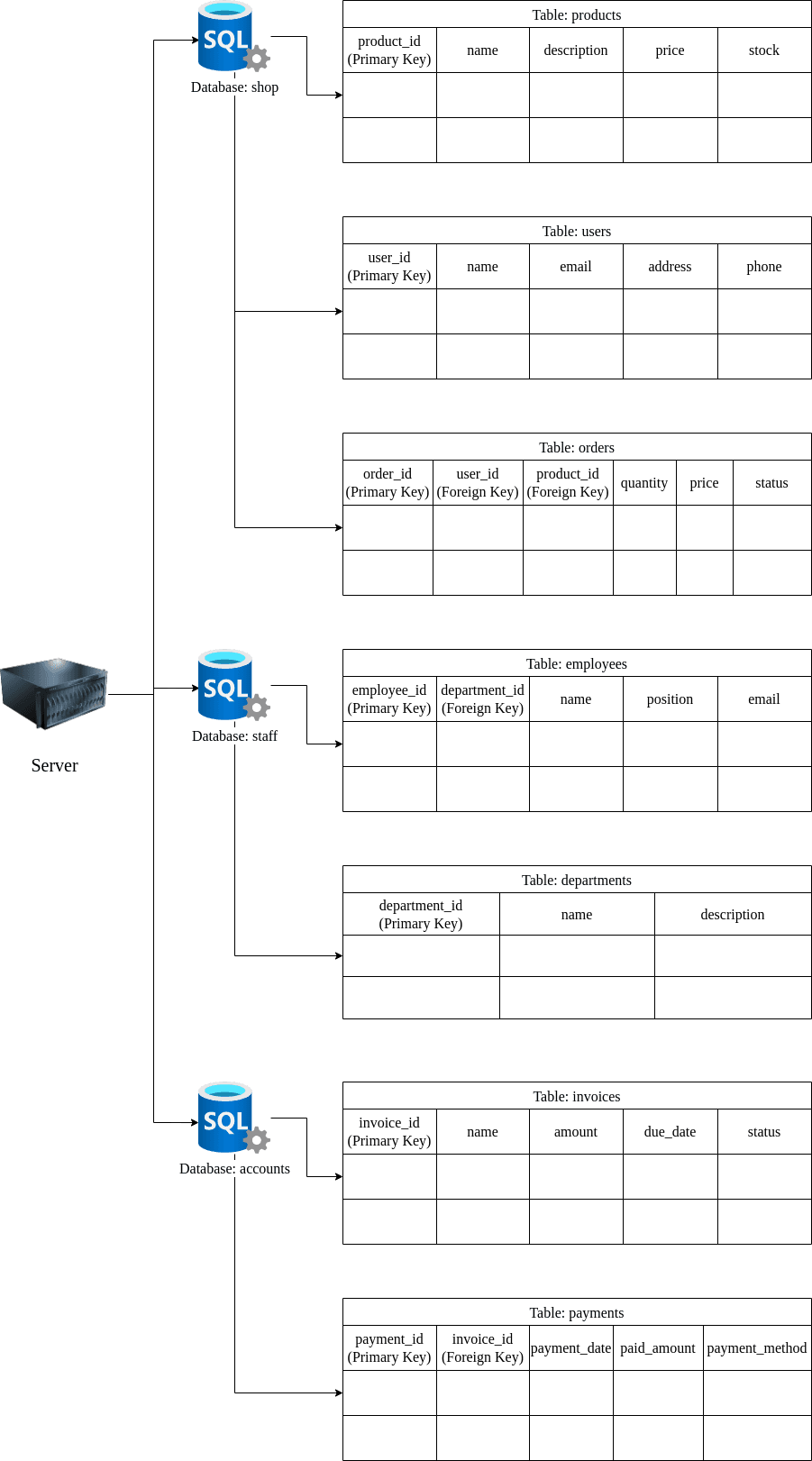
Now, let’s focus on the products table as an example.
| product_id | name | description | price | stock |
|---|---|---|---|---|
| 1 | milk | Fresh cow milk | 2.99 | 50 |
| 2 | egg | Chicken eggs | 1.49 | 100 |
| 3 | cheese | Cheddar cheese | 4.99 | 80 |
**Tables, Rows and Columns **
The table consists of rows and columns in a grid-like manner. In a table, a column going across from top to the bottom, while a row going across from left to right containing individual records. Each column has a unique name per table referred to as a field. When creating a table, you need to set the type of each data it will contain, whether it is a numeric, strings, or dates.
By setting the data type for each field we ensure that the incorrect data types input can be avoided. As a result, if users or applications try to enter the incorrect data types it will throw an error. A column may also have auto- increment feature enabled which is commonly applied to the primary key. So, if there is new data being added, the primary key will increment by 1 automatically.
From the table provided above, you can observe the milk, egg, and cheese products, with each piece of information displayed in a separate row. Based on the table, we can conclude that each row represents a single piece of data.
Relational database
In the introduction, we mention that there are many kinds of databases. They are often simplified as relational and non-relational databases. We also learn how the relational database uses tables to store the information. You might wonder, what is the reason behind its name, “relational”?
Let’s go back to the schematic figure above. If you look closely, each row has an identifier and it should be unique. For example, the products table has product_id, users table has users_id, and so on sets as the PRIMARY KEY. However, in other tables, we have quite similar IDs, identified as FOREIGN KEY. Foreign keys will be used to establish or enforce a link between the data in two tables. In SQL, these specific rules in certain fields are known as SQL constraints.
**SQL Constraints **
We also have learned that the data types are used to limit the type of data that can be stored in a table. Then, why do we still need constraint? To explain, let’s take the employees table. Assume that your client wants the following rules to be followed.
- Each employee has a unique identifier.
- The name field cannot be emptied. Hence, you need to enforce anyone who enters the data in this table to fill the name field. In other words, the “name” field is mandatory.
- Because each employee has an email address, ensure that each email is unique..
- Each employee belongs to different departments. To maintain data integrity, reference each employee’s department to the departments table.
As we can see, to fulfill these requirements, it would be insufficient to o nly rely on the data types. Hence, we need the constraints to solve this.
**PRIMARY KEY **
The “employee_id” field uniquely identifies each employee. You can set the “employee_id” as the primary key for the table, ensuring that each employee has a unique identifier. This constraint prevents duplicate or null values in the “employee_id” field.
**NOT NULL **
The “name” field represents the name of the employee. To ensure that the name is always provided, you can apply a “NOT NULL” constraint to the “name” field. This constraint ensures that every record in the table must have a non-null value for the “name” field.
**UNIQUE **
The “email” field stores the email address of each employee. To ensure that each email address is unique across the table, you can apply a “UNIQUE” constraint to the “email” field. This constraint prevents duplicate email addresses from being entered into the table.
**FOREIGN KEY **
In the employees table, you have a field called “department_id” that refers to the department each employee belongs to. To maintain data integrity, you can apply a foreign key constraint to the “department_id” field, referencing the departments table. This constraint ensures that the values in the “department_id” field must exist in the referenced table’s primary key column.
By applying these constraints to the employees table, you can ensure that only valid and consistent data is stored. Constraints help prevent data inconsistencies, maintain referential integrity, and improve the reliability of the database.
In fact, there are several more constraints that you can use for various purposes, such as CHECK to check whether a certain column follows a Boolean expression or DEFAULT to fill a column with a fixed or default value.
**What is SQL? **
SQL (Structured Query Language) is a language specifically used for querying the database, which is often referred to as statements. The following examples are based on a MySQL database. Despite its similarity, each database can have its own syntax and minor variations. It is also important to note that the syntax used for SQL is not case sensitive. You should also include the semicolon (;) to end a statement.
**Database **
SHOW DATABASES;
See all available databases.
CREATE DATABASE database_name;
Create a new database.
USE database_name;
Use a particular database named database_name;
**Table **
You can see all existing tables with the following statement.
SHOW TABLES;
Showing all tables in a database.
Before making a table, you have to specify how many columns you want and the data types of each column. For example, if you want the table template you can use the following statement.
CREATE TABLE department (
department_id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(50),
description VARCHAR(100)
);
To fill out all the empty fields, you can use the following statement.
INSERT INTO department (department_id, name, description)
VALUES
(1, 'IT', 'Information and technology'),
(2, 'Sales', 'Sales and growth'),
(3, 'Marketing', 'Promotions and advertising');
There are lots to cover when it comes to data processing in SQL databases. For this reason, we are going to focus only on what is relevant to SQL injection attack and understanding why some of the SQL payload, despite looking a bit weird, may work.
**SELECT **
SELECT is used to retrieve data from the database. For now, let’s use the departments table as an example.
SELECT * FROM departments;
| department_id(Primary Key) | name | description |
|---|---|---|
| 1 | IT | Information and technology |
| 2 | Sales | Sales and growth |
| 3 | Marketing | Promotions and advertising |
This statement will show the records from the departments table. The asterisk symbol (*) means that we want to retrieve all columns. Because we specify the table we would like to use, which is “departments”, we will retrieve back all columns that belong to the department table.
SELECT name FROM departments;
| department_id(Primary Key) | name |
|---|---|
| 1 | IT |
| 2 | Sales |
| 3 | Marketing |
We can also specify the column we want by defining the column in the SELECT query.
SELECT * FROM departments WHERE name != ‘Marketing’;
| department_id(Primary Key) | name | description |
|---|---|---|
| 1 | IT | Information and technology |
| 2 | Sales | Sales and growth |
You can also filter out some data (rows) so it will be excluded from the retrieved results. Since we use NOT EQUAL symbols (!=), the returning rows will SELECT every row whose “name” is NOT EQUAL to “Marketing”.
SELECT * FROM departments WHERE name == ‘IT’ OR name == ‘Marketing’;
| department_id(Primary Key) | name | description |
|---|---|---|
| 1 | IT | Information and technology |
| 3 | Marketing | Promotions and advertising |
With OR, you can specify the individual data you want. In this case, we want data named “IT” or “Marketing.
SELECT * FROM departments WHERE name == ‘IT’ AND description == ‘Information and technology’;
| department_id(Primary Key) | name | description |
|---|---|---|
| 1 | IT | Information and technology |
This statement only returns the rows where the username is equal to “IT” and the description is equal to “Information and technology”.
SELECT * FROM departments WHERE name like ‘Ma%’;
| department_id(Primary Key) | name | description |
|---|---|---|
| 3 | Marketing | Promotions and advertising |
The LIKE clause allows you to specify data that isn’t the exact match. In this case, we want to look for the department whose name starts with ‘Ma’. Then, we allow any characters that follow our mentioned characters which is “Ma” by placing the wildcard character represented by the percentage sign (%).
SELECT * FROM departments WHERE name like ‘%ing’;
| department_id(Primary Key) | name | description |
|---|---|---|
| 3 | Marketing | Promotions and advertising |
In a similar way, we can also search for data whose name ends with “ing”. Then, we place the wildcard character (%) in front of the word we are looking for.
SELECT * FROM departments WHERE name like ‘%ale%’;
| department_id(Primary Key) | name | description |
|---|---|---|
| 2 | Sales | Sales and growth |
We can also place the wildcards on both start and end of the partial word we want. Since the “Sales” contains the word “ale” in it, it will produce the results like the above.
**UNION **
The UNION statement combines the results of multiple SELECT statements, ensuring that they have the same number of columns, with matching data types, and in the same column order. If you find this quite confusing, let’s see the below example.
Assume that we have new table containing information about the sub department of marketing called “subdepartments”.
| sub_department_id(Primary Key) | subname | description |
|---|---|---|
| 1 | Market Research | Conducts market research and analysis |
| 2 | Public Relation | Handles public relations and communications |
| 3 | Digital Marketing | Manages digital marketing campaigns |
If we want to combine this new table with the existing one, like the departments table, we can use the following statement.
SELECT name, description FROM departments UNION SELECT subname, description FROM subdepartments;
Because both tables use the same amount of columns, and both “name” and “subname” have the same data type which is string, the data can be retrieved. Otherwise, it will throw an error. The table will then be combined into a new table.
| name | description |
|---|---|
| IT | Information and technology |
| Sales | Sales and growth |
| Marketing | Promotions and advertising |
| Market Research | Conducts market research and analysis |
| Public Relation | Handles public relations and communications |
| Digital Marketing | Manages digital marketing campaigns |
**INSERT **
The INSERT statement is used when we want to insert new data into the table. Say that we want to insert a new department called “Finance”. We need to fill each column with the value we want. In this example, we provide a string value “Financial operations” for description.
INSERT INTO departments (name, description) VALUES (‘Finance’, ‘Financial operations’ );
| department_id(Primary Key) | name | description |
|---|---|---|
| 1 | IT | Information and technology |
| 2 | Sales | Sales and growth |
| 3 | Marketing | Promotions and advertising |
| 4 | Finance | Financial operations |
**UPDATE **
The UPDATE statement tells the database to update one or more brown within the table. If we want to update the particular field, we can use the following statement.
UPDATE departments SET description = ”Handling financial operations” WHERE name = ”Finance”;
| department_id(Primary Key) | name | description |
|---|---|---|
| 1 | IT | Information and technology |
| 2 | Sales | Sales and growth |
| 3 | Marketing | Promotions and advertising |
| 4 | Finance | Handling financial operations |
**DELETE **
As the name suggests, DELETE is used for delete one or more rows in a table. For example, assume that you want to delete the rows named ‘Finance’. You can simply use the following statement.
DELETE FROM departments WHERE name=”Finance”;
| department_id(Primary Key) | name | description |
|---|---|---|
| 1 | IT | Information and technology |
| 2 | Sales | Sales and growth |
| 3 | Marketing | Promotions and advertising |
Be cautious when using this statement! If you don’t specify the row or the data you want to delete, you will delete ALL data in the table.
DELETE FROM departments;
**ORDINAL POSITION **
When working with a table, you can also set the order by using the column based on its ordinal position. If we take the departments table as an example, we can write a statement like this.
SELECT * FROM departments ORDER BY 2;
| department_id(Primary Key) | name | description |
|---|---|---|
| 1 | IT | Information and technology |
| 3 | Marketing | Promotions and advertising |
| 2 | Sales | Sales and growth |
The ordinal position starts from left to right. By this definition, we can conclude that “department_id” belongs to ordinal position 1, “name” to 2, and description to 3. As you can see on the above table, the row order number 2 and 3 are switched because the order will be sorted by column 2 which is “name” following the alphabetically order. If you change the ordinal position to 3, the order will be the same. However, it will be sorted by the “description” field instead of the “name” field. Surely, if you try to use an inexistence ordinal position like 4, it will throw an error.
Alternatively, you can also use the ordinal position when declaring the SELECT statements. Thus, we can choose any column by its corresponding ordinal position without having to know or define the name of the column.
**COMMENT **
In any programming language, it is very common to use comments to add explanatory or descriptive text. SQL is no different. We can use the double dash sign (—) so any query comes after these symbols will be ignored when executing the query.
Look at the following statement.
DELETE FROM departments WHERE name=”Marketing”;
DELETE FROM departments;-- WHERE name=”Marketing”;
As you can expect, the first statement will only delete the row with the name “Marketing” in it. However, the second statement works very differently. By adding the comment, we ignore the WHERE clause. In other words, we only execute the following statement.
DELETE FROM departments;
In this example, we also add the semicolon to tell the database that the query ends. Otherwise, it won’t execute the statement and the database will think that the query is not finished yet.
**Conclusion **
Finally, there is still a long way to go to learn about DBMS especially, relational databases. What we have learned today is quite basic knowledge of SQL. In relation to SQL injection, these basics would probably be enough to let you at least understand why some sign like double dash (—) or percentage sign is common in SQL injection payload.
While it seems a little bit odd like ' OR 1=1;-- , this query is simply
representing the true value, since 1=1 is true. It will then be combined with
an OR operator to let the query return as true, which satisfies web
application logic thus bypassing the access. In spite of there being tons of
SQLi payload, the main objectives are the same, manipulating the logic so it
will return true. This is mostly the case in an attempt to bypass the
authentication form with SQL injection.
But, it’s not always the case. In certain conditions, SQL injection can also be used to retrieve sensitive information within the database. In the end, hopefully, this article will help you understand why some SQL injection payloads are like that.